Do you hear it? Meet AVIP-Bench
A controlled benchmark for evaluating intuitive physics from video & sound.
Objects crash, bounce, and shatter - our benchmark of audiovisual object drops probes whether models benefit from adding sound when reasoning about physics.
What is AVIP?
A tiny, controlled benchmark with triplet videos per clip: A audio-only, V video-only, and AV audio+video. Tasks: object, material, outcome. We check top‑1 predictions vs. ground truth and look for cross‑modal gains.
- 📦 Minimal, reproducible clips
Short single‑impact scenes recorded in a controlled setup. - 🔊 Modality toggles
Each clip exists as A, V, and AV to test true audio usage. - 📈 Metrics
Top‑1 accuracy per task and an AV − max(A,V) cross‑modal gain. - 🧪 Probe‑style prompts
Strict label sets & JSON outputs to avoid prompt drift.
Method (short)
- For each clip, run models on A, V, and AV variants with the same instruction-style prompt.
- Decode model outputs into
{object, material, outcome}and compare against labels. - Compute per-task Top-1 and Top-5 accuracy and cross-modal gain per clip and in aggregate; additionally report calibration/confidence metrics (ECE, Brier, margin, entropy, Top-1 probability) and probing-based audio reliance via fixed cue selection and A/V/AV consistency; all metrics computed on the paired clip set (A∩V∩AV) with 95% confidence intervals.
Leaderboard
Per‑Modality (A / V / AV)
| Model | Modality | N | Top‑1 Acc (%) | Updated |
|---|
Example clips and Plots
paperbox, material=cardboard, outcome=bounceCross-Modal Gain (CMG)
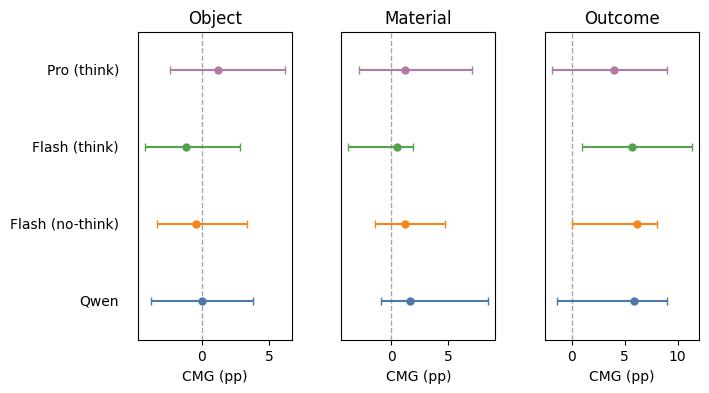
Look for positive values: these mean AV was better than either audio or video alone. Gains usually appear for outcome prediction, but rarely for object or material recognition.
Average modality attribution (AV)
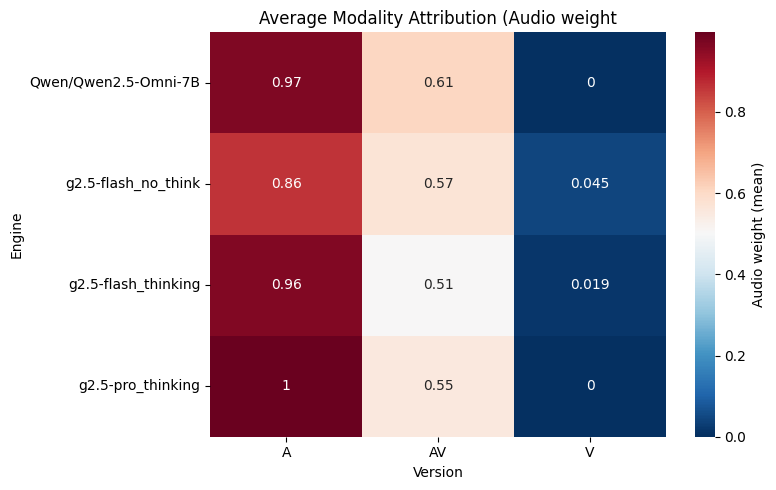
What to look for: Red = model relies more on audio, Blue = model relies less.
Engines that “listen” more may gain on outcome prediction, but not always.
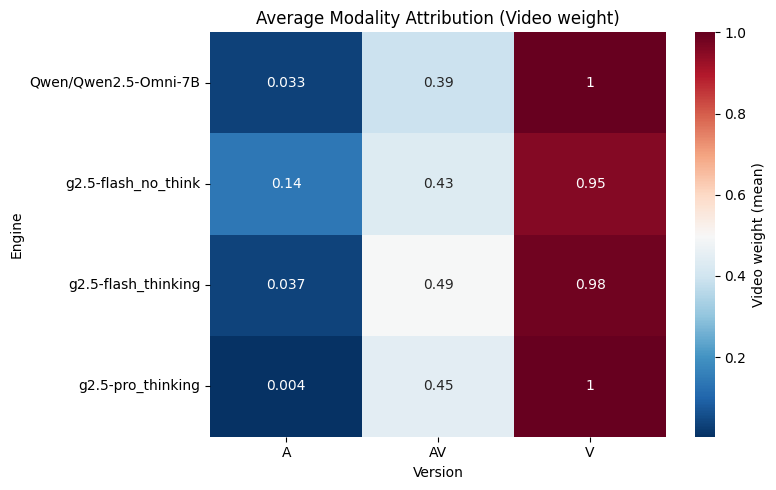
What to look for: Red = model relies more on video, Blue = model relies less.
Engines that “look” more often ignore sound, which can explain weak cross-modal gains.
Top-1 accuracy by task
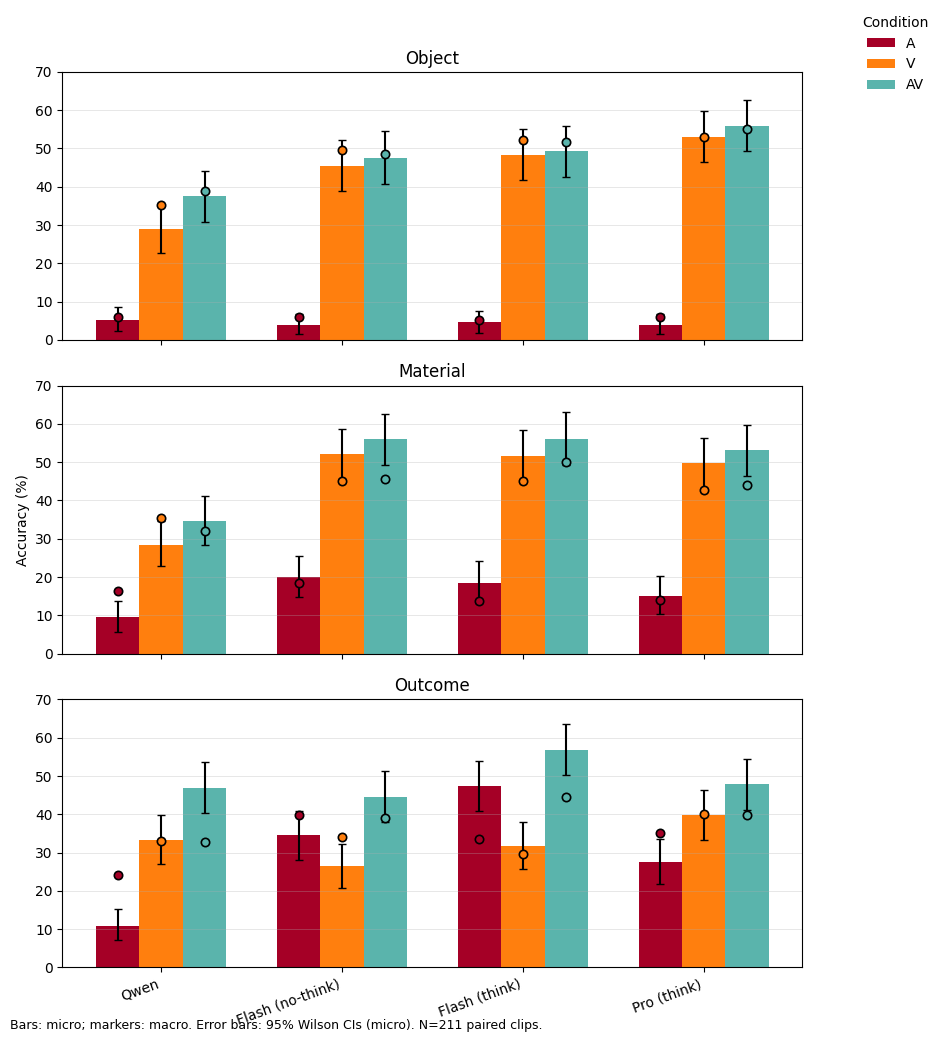
What to look for: V is usually highest; AV improves over A and sometimes nudges past V on outcome.
Big gaps A→AV mean sound is helpful; AV≈V means little extra benefit.
Contact
Questions? bramo.g@protonmail.com